Hadoop Client
Apache Hadoop is an open source framework that supports data-intensive distributed applications. Hadoop has many parts, but two are fundamental:
-
MapReduce is the framework that understands and assigns work to the nodes in a cluster. MapReduce divides the application into many fragments of work, each of which can be executed or re-executed on any node in the cluster.
-
HDFS (Hadoop File System) spans all the nodes in a Hadoop cluster for data storage.
The OrangeFS Hadoop Client is an HCFS plug-in which allows you to run Apache Hadoop version 1.2.1 and 2.6.0 with the OrangeFS distributed file system replacing Hadoop’s HDFS filesystem. Together, these two open source products can perform massive computations on the petabyte scale. OrangeFS also permits modification of data within the file system.
**Notes **You may also configure an existing Hadoop cluster using HDFS
as the default distributed file system to use OrangeFS as an alternative
storage solution.
Other versions of Apache Hadoop 1.x.x and 2.x.x will likely work with
the OrangeFS Hadoop Client but have not been fully tested. Brief
instructions for building the OrangeFS Hadoop client for a particular
Hadoop release are provided in the setup guides.\
Planning For Installation
Before you begin installing the OrangeFS Hadoop Client, you must select either an HPC or a traditional Hadoop storage option to use with the OrangeFS Hadoop Client. You can then preview the system and software requirements before moving on to the appropriate installation topic.
Understanding the Architecture
The basic design that enables MapReduce to work with OrangeFS integrates the OrangeFS Hadoop Client, the OrangeFS Java Native Interface (JNI) Shim, and the OrangeFS Direct Interface (DI).
Apache Hadoop is designed to support file systems other than HDFS through an abstract file system API. An implementation of this API, the OrangeFS Hadoop Client enables MapReduce to interface with the OrangeFS JNI Shim.
The OrangeFS JNI Shim utilizes the JNI, a programming framework that enables Java code running in a Java Virtual Machine to interface with native programs. In this case, the Java code is the OrangeFS Hadoop Client and the native code is the DI, with their interaction facilitated by the OrangeFS JNI Shim.
The OrangeFS DI is a Linux client interface written in C, which enables POSIX-like and direct system calls to the OrangeFS API, directing operations to OrangeFS data/metadata servers.
Understanding Storage Options
HPC vs. Traditional
You can set up the OrangeFS storage for your OrangeFS Hadoop Client in two ways.
Setup Options
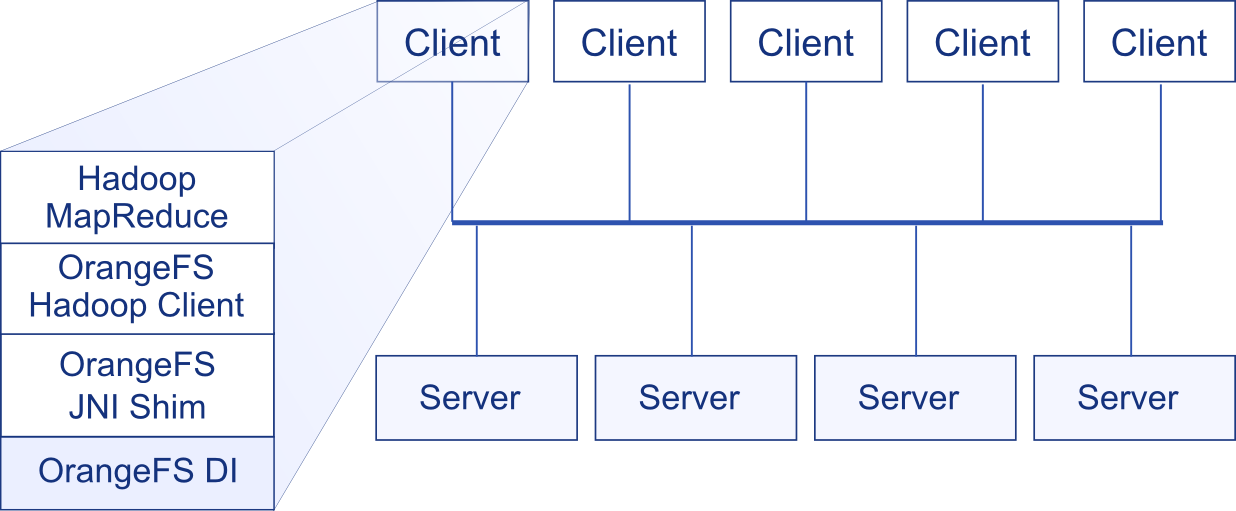
HPC
In this setup, Hadoop MapReduce accesses an OrangeFS file system through a single mount point to any of the OrangeFS servers.
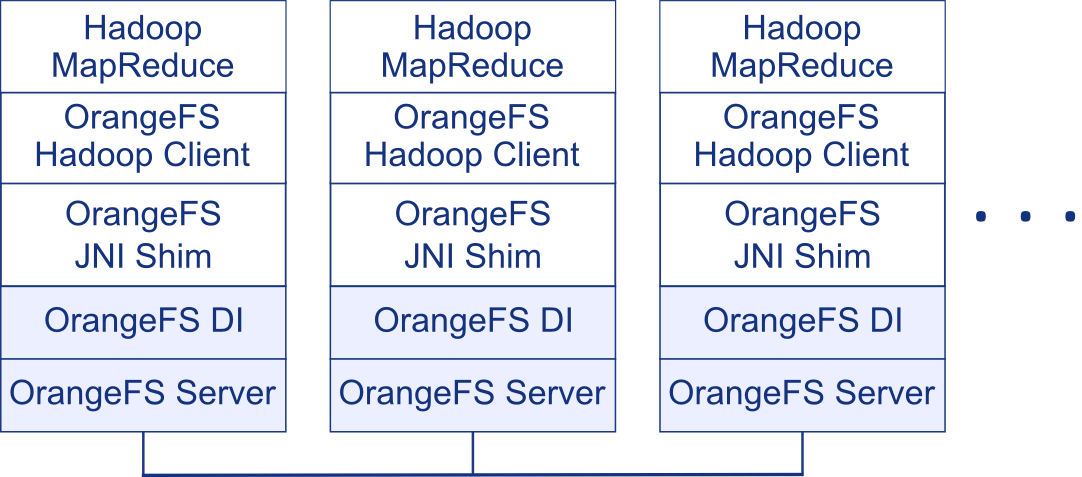
Traditional Hadoop
This setup simulates a traditional Hadoop installation, running a client and server program on each server in an OrangeFS cluster. This model represents the colocated compute and storage resources typical of most Hadoop clusters.
Linux Operating System
All server and client systems should use the same distribution of Linux. Guidelines for selecting a Linux distribution in Common System Requirements also apply to any systems used with the OrangeFS Hadoop Client.
Note For consistency, all topics about the OrangeFS Hadoop client use RHEL command line syntax wherever distribution-specific commands are required.
Common System Requirements
The HPC and the Traditional Hadoop installation configurations share a number of common requirements.
Preparing the Build System
Many of the instructions will prepare the OrangeFS Hadoop Client build system, including downloading, installing and configuring both Hadoop and OrangeFS. For both configurations, the administrator should select a single node out of the desired pool of nodes which will run MapReduce to act as the build system. Some tasks affect all clients, while others are focused on the single build system. This will produce a directory of software that must be copied from the build system node to the desired installation directory on each client node.
JDK
The build system requires the Java Development Kit (JDK) to build the OrangeFS Hadoop Client and OrangeFS JNI Shim.
**Note **For additional guidance on the appropriate JDK version, consult the Apache Hadoop recommendations.
Maven
To build the OrangeFS Hadoop Client, Maven must be installed on the build system.
Preparing Individual Client Nodes
JRE or JDK
While some Apache Hadoop related projects require the JDK for proper functionality (Sqoop, for example), only the Java Runtime Environment (JRE) is required to run MapReduce on client nodes. Your requirements will determine which one you should install.
**Note **It might be easiest to install the JDK on all client nodes, which produces no adverse results.
Hadoop Binaries
The Hadoop binaries are required to “run” Hadoop and use the OrangeFS Hadoop Client. You must download, extract, and copy the Hadoop binaries archive to each node.
System Variables
On each client node, you must eventually set the environment variables LD_LIBRARY_PATH, JNI_LIBRARY_PATH, and PVFS2TAB_FILE to run MapReduce with OrangeFS.
Installation Requirement Differences
Installation instructions are separated into two topics, according to your selected storage option. Following are some of the differences in their content.
HPC Setup
- Assumes that OrangeFS servers have already been configured and installed on the storage cluster. For more information on completing that setup process prior to setting up the OrangeFS Hadoop Client, see the Quickstart Guides or Add Servers.
- Hadoop was not originally designed to work in a scheduled HPC environment, but you can use a customized version of myHadoop, myHadoop-orangefs, with PBS to support on-demand clusters.
- Additional steps are required to incorporate myHadoop-orangefs here. This approach has been tested with PBS Professional version 12.0.0.x and myHadoop-orangefs version 0.1.
Traditional Hadoop Setup
- Assumes that you will configure and install OrangeFS client and server libraries/binaries on all desired nodes in your cluster.